
The Rundown
The original site sacred-texts.com is built entirely using plain HTML – no stylesheets. The books are broken up into pages that require a link click to get to the next page of the book. Some of the pages are extremely short (just a sentence or two), requiring hundreds of clicks to read a small portion of a given book. Here is an example of the reading experience:

An example of a book with very short chapters and the user experience it provides
I purchased the USB archive of the entire collection hoping this would give me plain text documents of all the text, but instead I received all the individual html files – essential a carbon copy of the site. With such a poor and annoying reading experience, I decided to build my own reading solution for these texts to enjoy for years to come.
The Plan
- Design the Backend – build a backend that accounts for the wide variety of content and formatting in the book archive.
- Scrape the data – Create a scraping script using BeautifulSoup to collect and store the texts in the database. This script will need to account for the variability and lack of consistency in the markup of the HTML files.
- Build the App – Once the data is stored in the database, it can be easily accessed and displayed by the frontend application, providing a user-friendly reading experience for the catalog of texts.
The Solution
Step 1: Design the Backend
Build an app that makes it easy to read any text from the library. This is how the backend will be setup. The database for the reader app is simple but accounts for the variance in all the books.
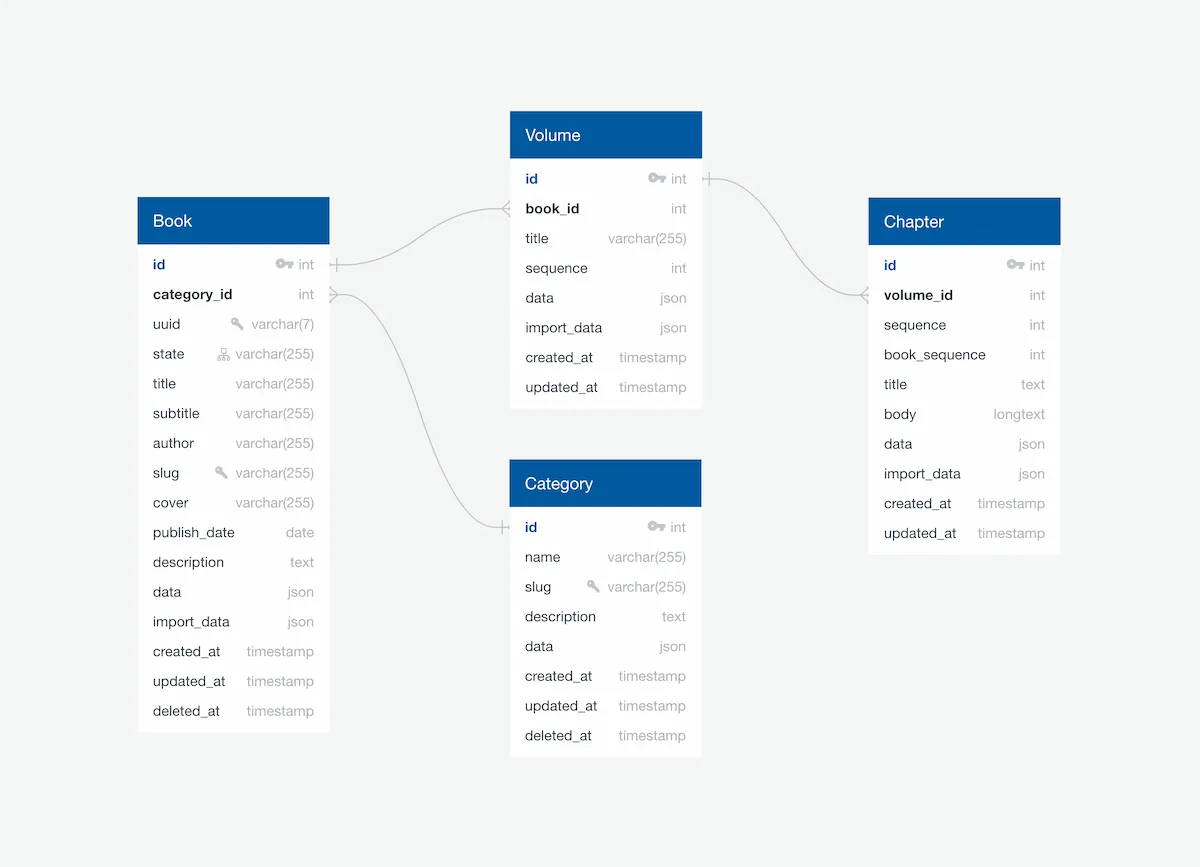
An ERD diagram for the backend database architecture of the Archive Reader app
Step 2: Scrape the Data
With all the books/texts are individually coded HTML pages without classnames nor a unified structure for elements like headers, table of contents and navigation. This made the content uniquely challenging to scrape and organize into a database. With more than 1700 titles and 100k chapters (pages), this stage required several iterations to the scraping logic given the variability and lack of consistency in the markup.
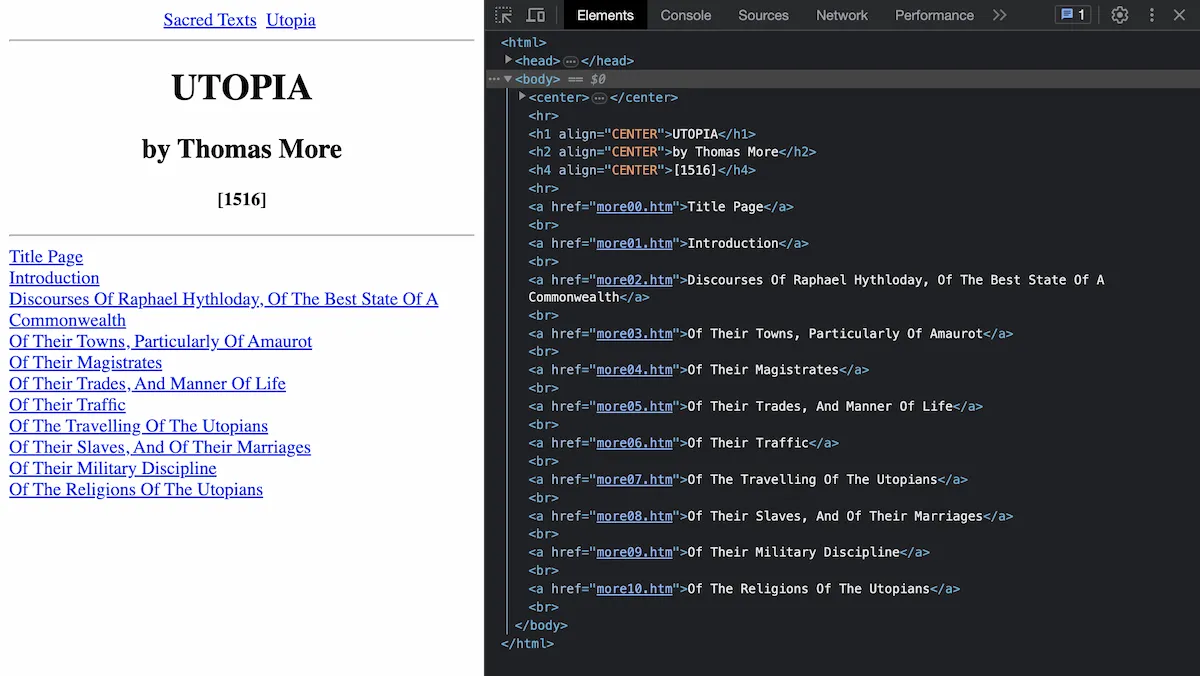
An example of the HTML structure from a given text
Step 3: Building the App
Once the data is stored in the database, it can be easily accessed and displayed by the frontend application, providing a user-friendly reading experience for the sacred texts.
There app consists of 3 primary pages here:
- Index page – the homepage essentially where we display a portion of the catalog and allow a user to search and/or browse through the archive of texts.
- Category page – Another more refined list of texts within a certain category, topic, or alphabetical letter.
- Reader page – the final page is the actual reader view – the main reason for the project. Here we create a clean, mobile-friendly, easy-to-use presentation of the text with dark-mode as the default for reading.
Archive Reader App Screenshots
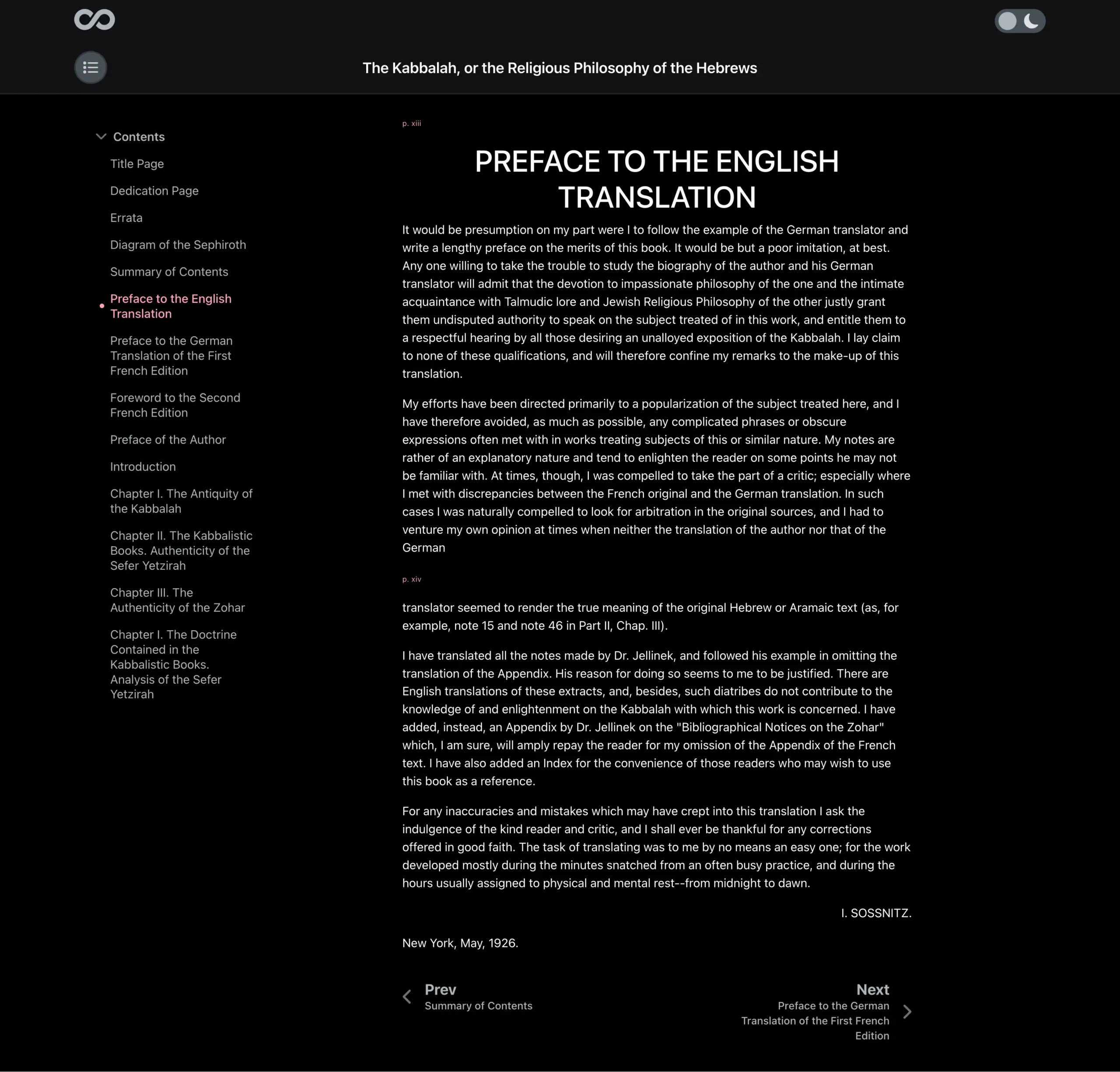
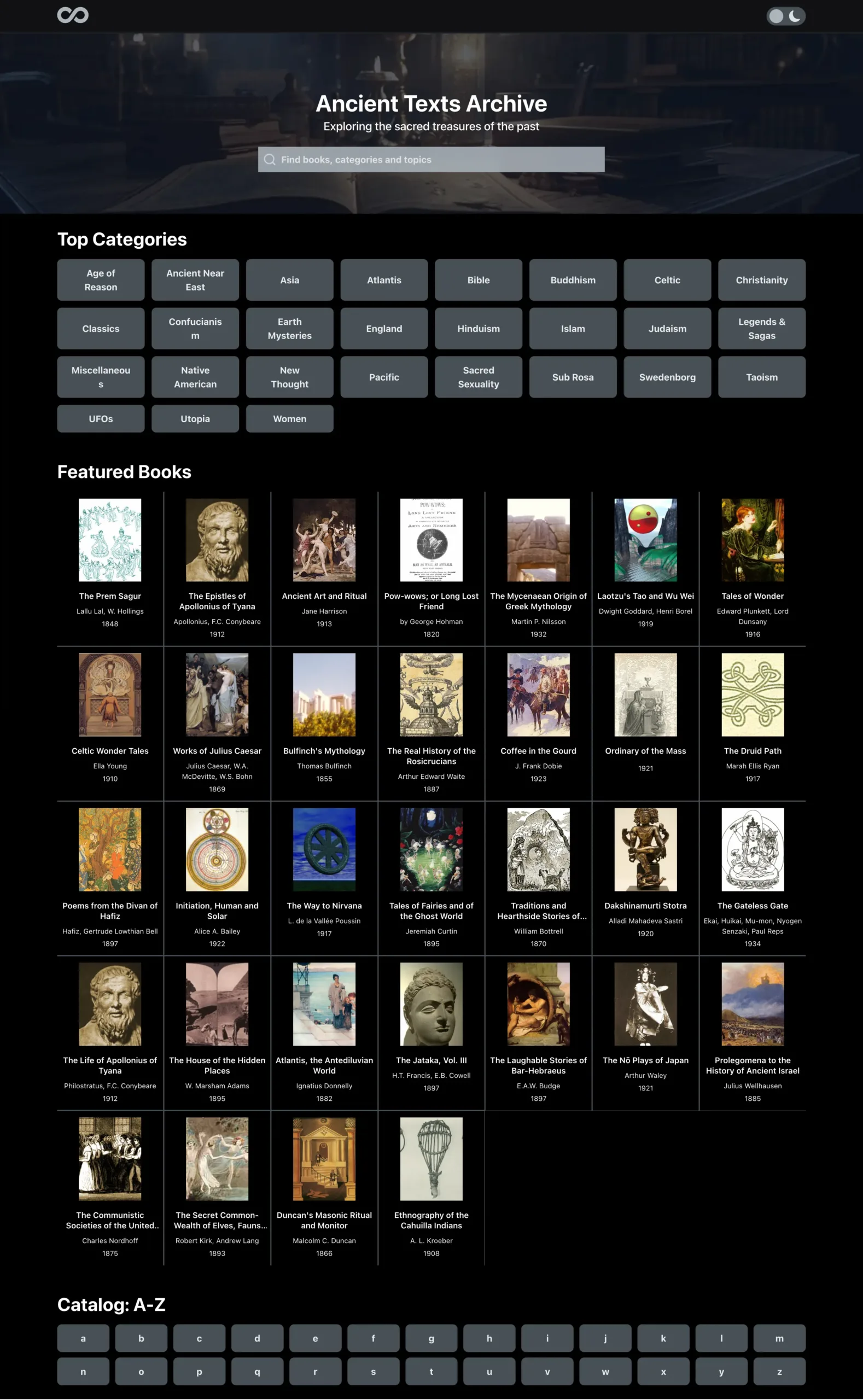
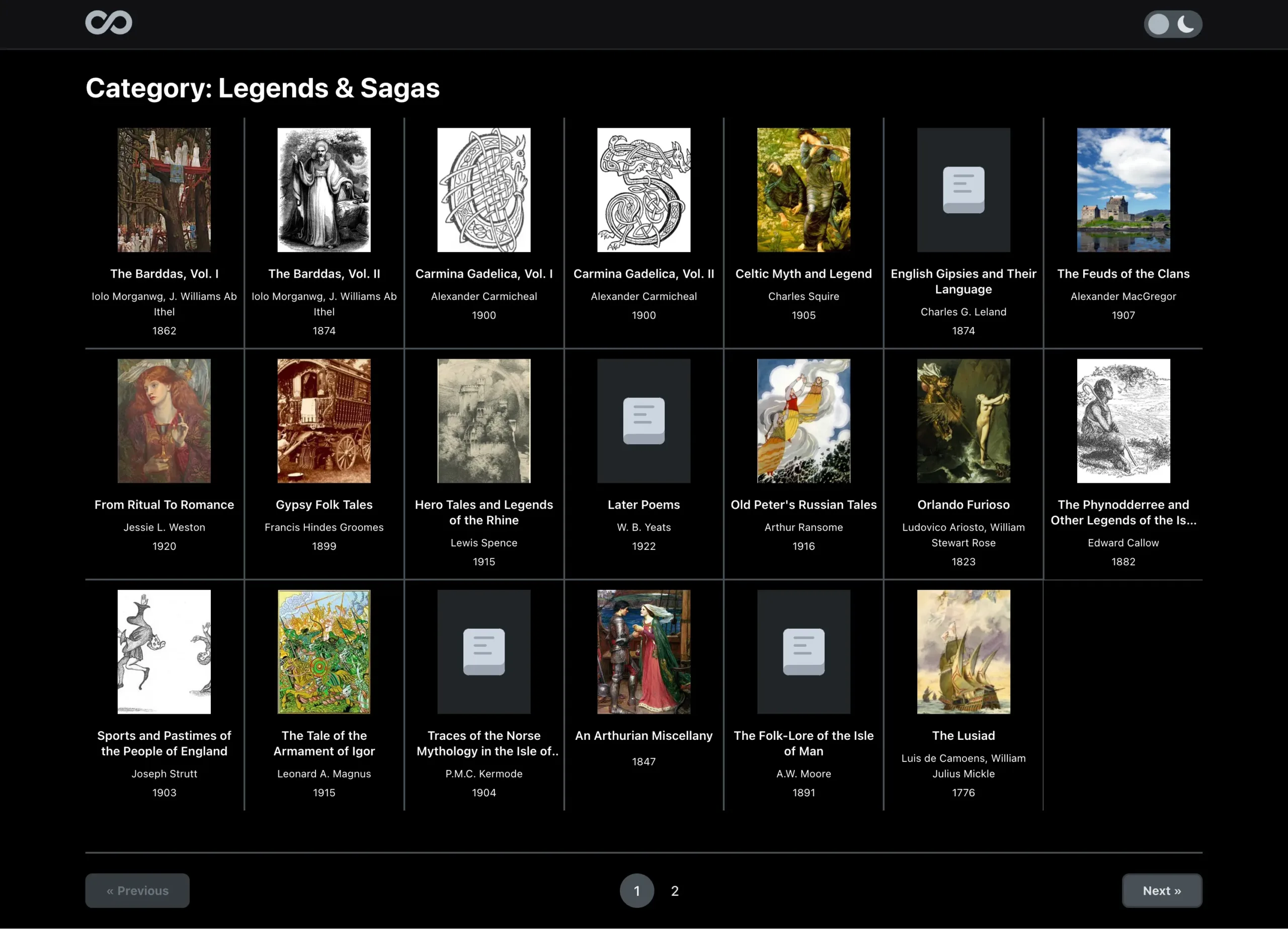
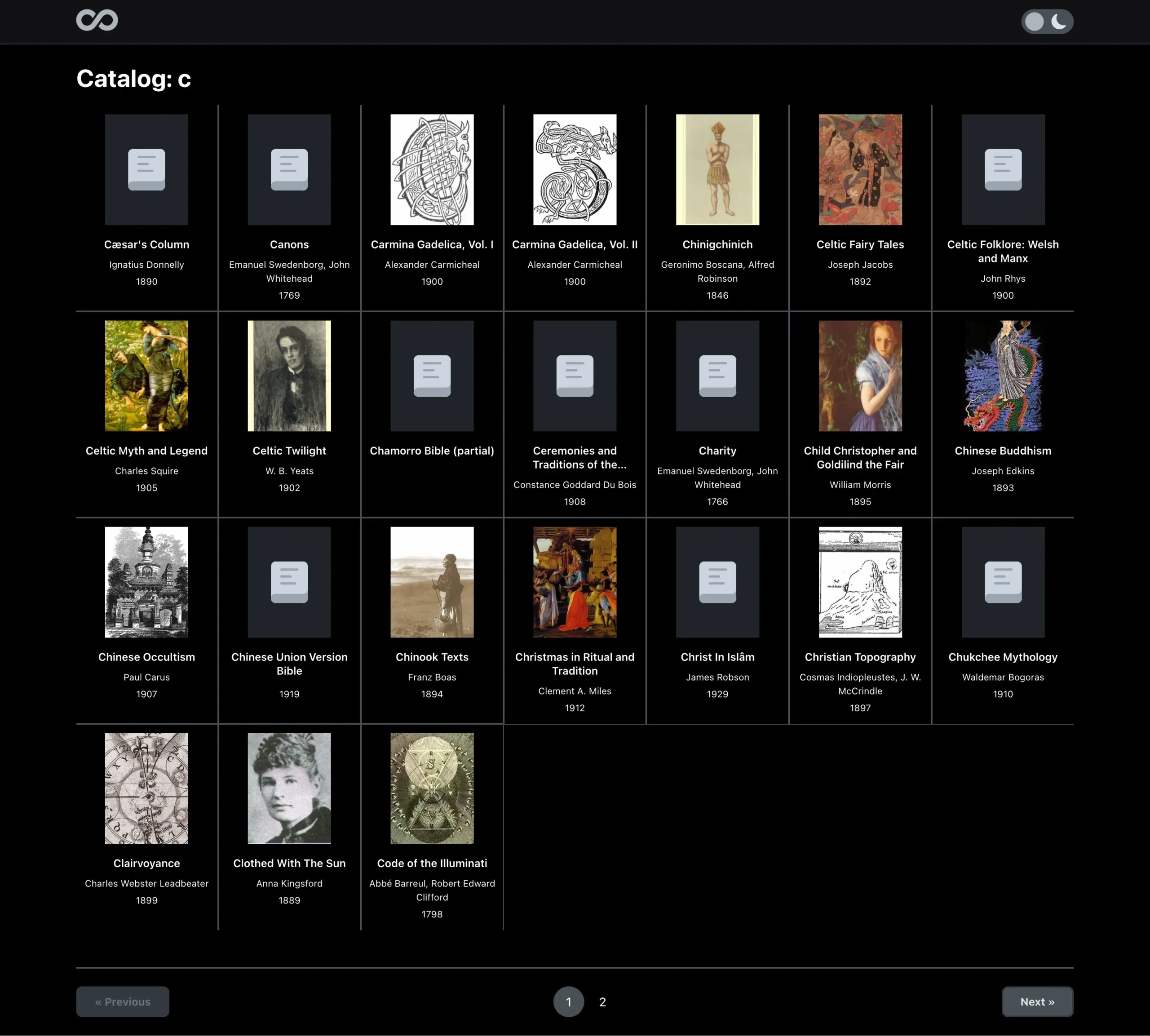
Overview
Developing a mobile-friendly reading solution for an archive of sacred texts, addressing HTML formatting issues, and establishing a structured database for an enhanced user experience.
Contents
Categories
Skills
Year
2023